Subasa - Adapting Language Models for Low-resourced Offensive Language Detection in Sinhala
Shanilka Haturusinghe
•
•
1 min read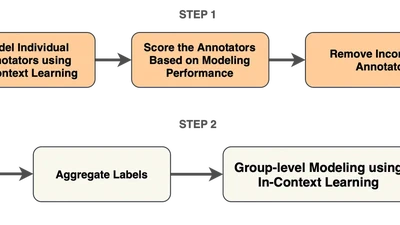
ARTICLE: Annotator Reliability Through In-Context Learning
Using LLMs to identify high-quality human annotators by checking if their labels are consistent with AI predictions—helping build better training data while preserving diverse …
Sujan Dutta
•
•
1 min readProRefine: Inference-Time Prompt Refinement with Textual Feedback
ProRefine automatically improves AI prompts during inference by having one AI agent give feedback to refine another agent's prompts—boosting accuracy by 3-37% and helping smaller …
Deepak Pandita
•
•
1 min read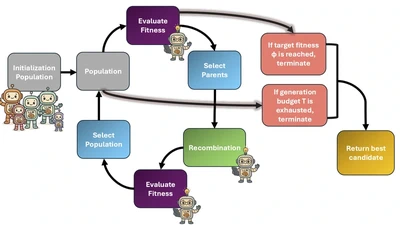
MultiGA: Leveraging Multi-Source Seeding in Genetic Algorithms
Mixing outputs from multiple LLMs (GPT-4, DeepSeek, etc.) using genetic algorithms to evolve better solutions for complex reasoning tasks—like breeding the best answer from diverse …
Isabelle Diana May-Xin Ng
•
•
1 min readBlind Spot Navigation in Large Language Model Reasoning with Thought Space Explorer
Note Presenting at NeurIPS (Math-AI Workshop) Date: December 6, 2025 Time: Sat 3:30 p.m. - 4:15 p.m. Location: NeurIPS 2025 - Workshop Upper Level Ballroom 6A Session Type: Poster …
Jinghan Zhang
•
•
1 min readRater Cohesion and Quality from a Vicarious Perspective
Asking people to predict how others with different political views would label content reveals hidden biases and improves data quality for content moderation AI.
Deepak Pandita
•
•
1 min read