Vicarious Offense and Noise Audit of Offensive Speech Classifiers: Unifying Human and Machine Disagreement on What is Offensive
Dec 2, 2023·
,,,·
1 min read
Tharindu Cyril Weerasooriya
Equal contribution
,Sujan Dutta
Equal contribution
,Tharindu Ranasinghe
Marcos Zampieri
Christopher M. Homan
Ashiqur R. KhudaBukhsh
Abstract
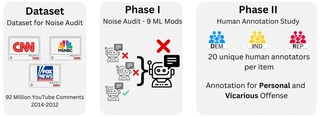
Offensive speech detection is a key component of content moderation. However, what is offensive can be highly subjective. This paper investigates how machine and human moderators disagree on what is offensive when it comes to real-world social web political discourse. We show that (1) there is extensive disagreement among the moderators (humans and machines); and (2) human and large-language-model classifiers are unable to predict how other human raters will respond, based on their political leanings. For (1), we conduct a noise audit at an unprecedented scale that combines both machine and human responses. For (2), we introduce a first-of-its-kind dataset of vicarious offense. Our noise audit reveals that moderation outcomes vary wildly across different machine moderators. Our experiments with human moderators suggest that political leanings combined with sensitive issues affect both first-person and vicarious offense.
Type
Publication
EMNLP 2023
We ran a massive experiment: 9 different AI content moderation systems analyzed 92 million YouTube comments about US politics. The results were shocking—different AI systems flagged wildly different content as offensive, with almost no consistency. When we asked humans to label the same content, political identity was a huge factor: Democrats and Republicans disagreed strongly on what’s offensive, especially on hot topics like abortion and gun rights. This proves that “offensiveness” isn’t a fact that AI can learn—it’s a subjective judgment shaped by values. Current content moderation practices that treat one group’s perspective as “truth” are fundamentally unfair.