ARTICLE: Annotator Reliability Through In-Context Learning
Mar 1, 2025·,,,,,·
1 min read
Sujan Dutta
Deepak Pandita
Tharindu Cyril Weerasooriya
Marcos Zampieri
Christopher M. Homan
Ashiqur R. KhudaBukhsh
Abstract
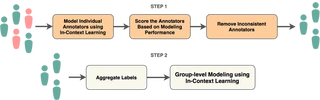
Ensuring annotator quality in training and evaluation data is a key piece of machine learning in NLP. Tasks such as sentiment analysis and offensive speech detection are intrinsically subjective, creating a challenging scenario for traditional quality assessment approaches because it is hard to distinguish disagreement due to poor work from that due to differences of opinions between sincere annotators. With the goal of increasing diverse perspectives in annotation while ensuring consistency, we propose
ARTICLE, an in-context learning (ICL) framework to estimate annotation quality through self-consistency. We evaluate this framework on two offensive speech datasets using multiple LLMs and compare its performance with traditional methods. Our findings indicate that ARTICLE can be used as a robust method for identifying reliable annotators, hence improving data quality.Type
Publication
AAAI 2025
When humans label data for AI (like deciding if a tweet is offensive), how do we know who’s doing good work versus who’s careless or biased? Traditional methods struggle because on subjective tasks, sincere people genuinely disagree. We built ARTICLE, which uses large language models to check if an annotator’s labels are internally consistent and align with what the AI predicts. This helps identify reliable annotators without silencing minority perspectives—crucial for building fair AI systems that don’t just reflect the majority view.