Subasa - Adapting Language Models for Low-resourced Offensive Language Detection in Sinhala
Shanilka Haturusinghe
•
•
1 min read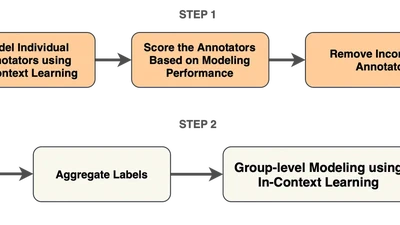
Using LLMs to identify high-quality human annotators by checking if their labels are consistent with AI predictions—helping build better training data while preserving diverse …
Asking people to predict how others with different political views would label content reveals hidden biases and improves data quality for content moderation AI.
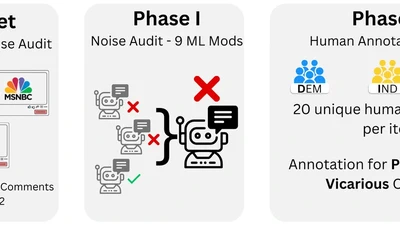
We ran a massive experiment: 9 different AI content moderation systems analyzed 92 million YouTube comments about US politics. The results were shocking—different AI systems …
Testing 9 different AI content moderation systems on 92 million YouTube comments reveals wildly inconsistent results, while human annotators show strong political bias—proving that …