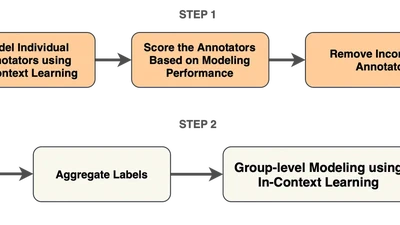
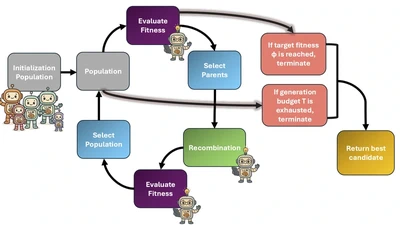
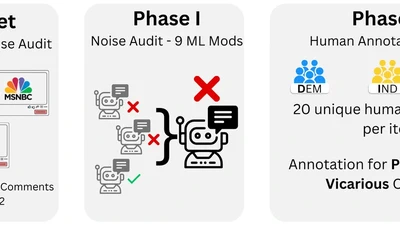
Hello! I am a Research Scientist at Accenture and a PhD graduate from the Lab for Population Intelligence at RIT, led by Professor Christopher Homan. My research focuses on ethical AI and the prediction of human disagreements in annotation using machine learning. Rather than treating annotation noise as a problem, my work leverages human rater disagreements to build more socially representative and bias-aware datasets. This is especially important, as recent advances in machine learning have uncovered bias risks for marginalized groups.
During my PhD, I’ve interned at Amazon Ads, Meta, and RPI (IBM Watson Project), where I developed models for handling weak human judgments and well-being in creator communities.
Beyond my research at RIT, I actively work with the University of Kelaniya in Sri Lanka to develop a national electronic medical record system, enabling scalable healthcare technology in resource-limited settings. I also have a background in sociolinguistics, with work on the evolution of Sri Lankan English across generations.
I am passionate about DevOps, building robust, end-to-end research systems. When not at my desk, I love cycling, photography, and discovering new places on my travels.